딥러닝을 한 번이라도 맛본 사람이라면,
이미지가 텐서 라는 형태로 변환되고 처리가 이루어진다는 것은 자명한 사실이다.
그럼 이 텐서라는 형태에서 다시 이미지 파일로 형태를 바꾸려면, 어떻게 해야 할까?
보기 쉬운 이미지를 위해, 그림판으로 28x28 사이즈의 이미지를 하나 색칠했다.
회색 부분은 #999999 이고, 줄이 쳐진 부분은 #555595 이다.

대충 이미지 하나를 생성했다. (28x28x3)
그럼 이 이미지를 이제 텐서 형태로 변환한다.
image_path 는 알아서 잘 지정하자. 절대경로로 하면 편하다.
값을 알아보기 위함이므로 normalize 는 진행하지 않는다.
출력은 넘파이 배열로 출력한다.
from PIL import Image
import torchvision.transforms as transforms
import torch
image_path = "img.png"
image = Image.open(image_path)
transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.ToTensor()
])
image_tensor = transform(image)
image_tensor = image_tensor.unsqueeze(0)
tensor_values = image_tensor.numpy()
with open("tensor_values.txt", "w") as f:
for layer in tensor_values:
for row in layer:
for value in row:
f.write(f"{value} ")
f.write("\n")
f.write("\n")
tensor_value.txt

텍스트 파일을 보면 알 수 있는 점이 있다.
다시 그림을 한 번 보자.

보면 오른쪽으로 1픽셀 정도 치우쳐져 있는 그림이다.
값을 한 번 보자.

0.33 .. 값은 첫 번째를 1번이라고 했을 때 14번부터 16번의 값을 가진다!
28x28 의 정 중앙이 14 라는 점을 보았을 때, 딱 1픽셀 밀려 있는 것을 확인 가능하다.
이번에는
0.33 ... 값이 가득한 부분을 한 번 본다.
위에서 부터 1번 row 라고 했을 때 7번에 위치한다.

잘 보면 첫 번째만 값이 이상한데, 이는 의도된 그림이다. 그림을 다시 보면 가장 처음 픽셀만 살짝 연한 것을 볼 수 있다.
따라서, 이 정보들을 보면, 텐서는

저 방향으로 하나의 row 를 끝날 때까지 읽고, 끝나면 다음 row를 출력한다고 보면 되겠다.

그리고 총 형태를 보면,
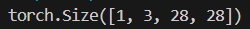
이다. 우리가 지금까지 봤었던 것은 한 차원의 값이다. 아마 RGB 중 R 값을 본 것 같다.
이는 B의 0.33 ... 값을 보면 더 잘 알 수 있다.
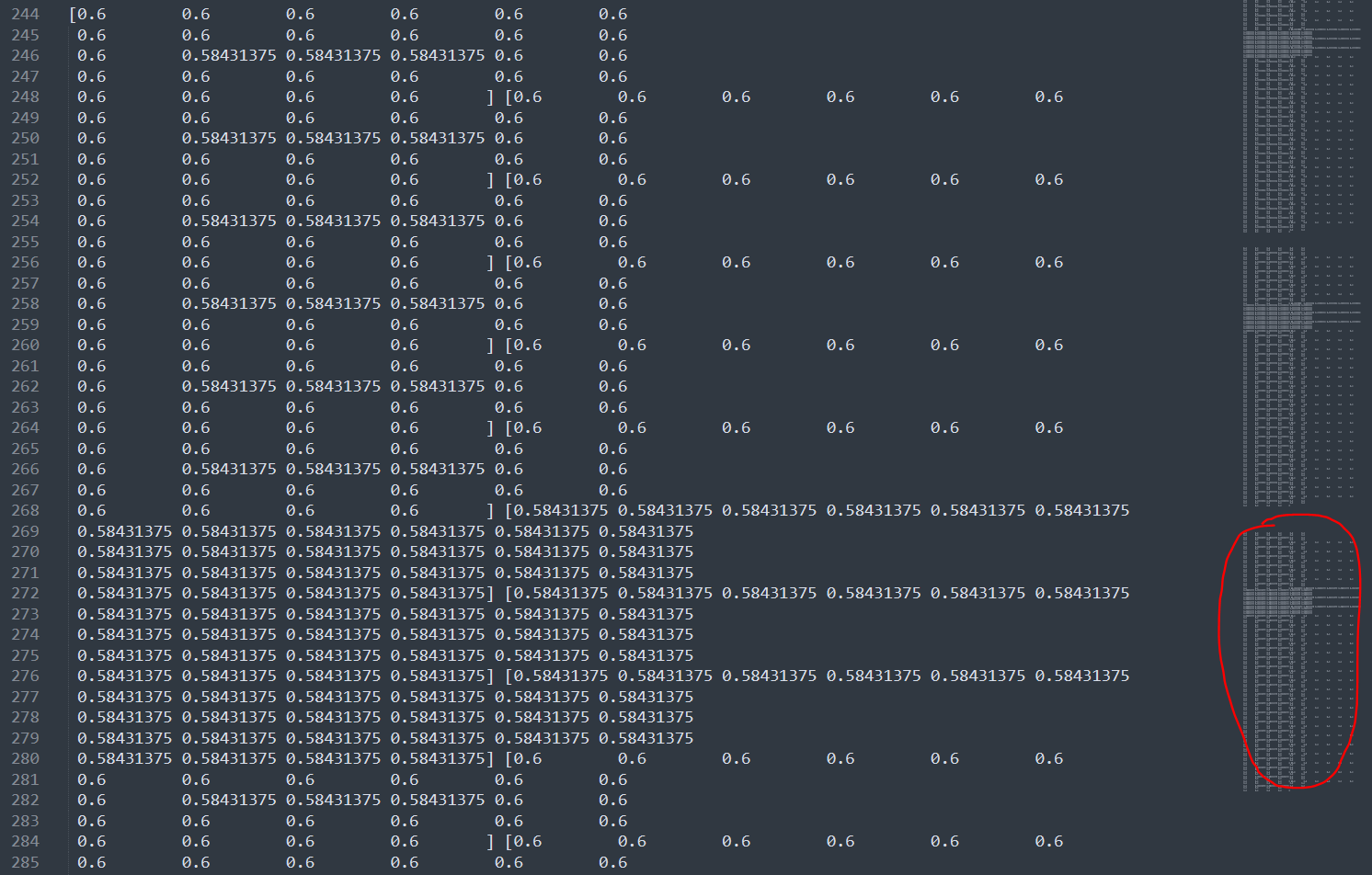
이쪽 부분만 0.58431375 로 값이 같은 것을 알 수 있다.
처음에 값 지정할 때 #555595 로 설정했기 때문에 혼자만 다르게 나오는 것을 볼 수 있다.
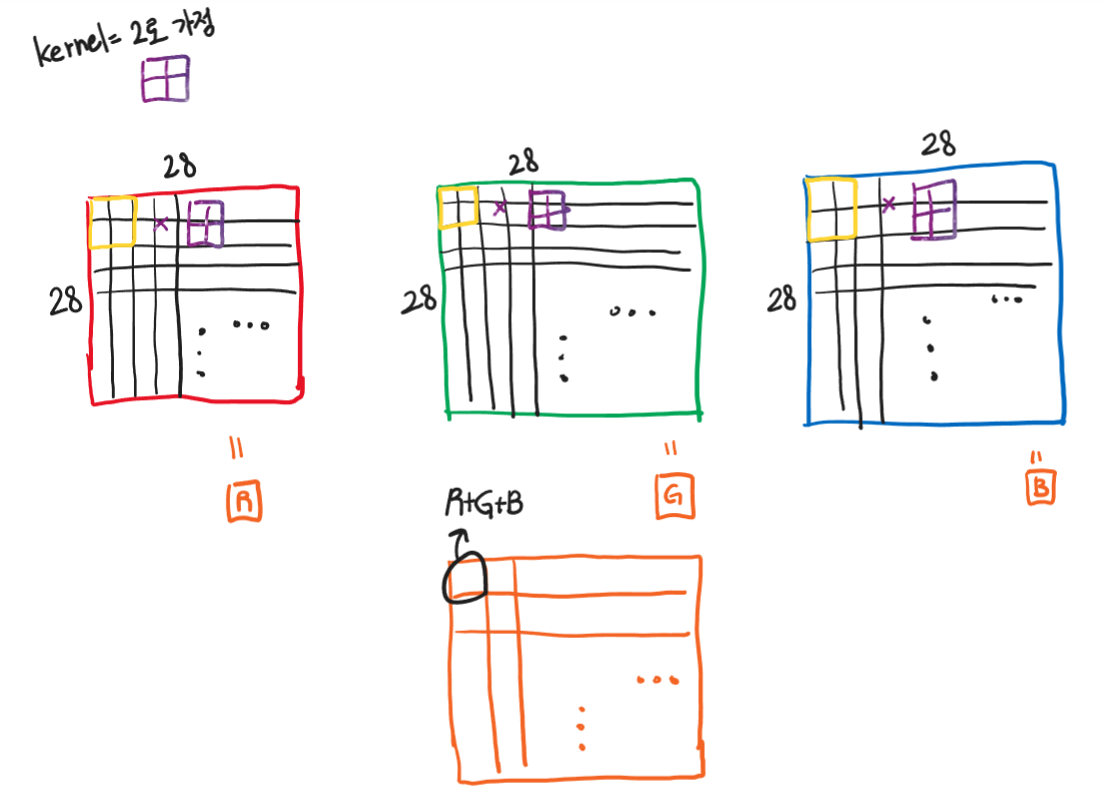
커널이 있으면 위 사진처럼 계산도 가능하겠다.
이제 다시 넘파이 배열를 이미지로 변환해 볼 차례이다.
하나 예시를 들어보면, #999999의 RGB 값은 (153, 153, 153) 이다.
153 을 RGB 범위인 255로 나누게 되면 0.6 이라는 값이 나오게 된다.
#555595 는 어떨까? (85, 85, 149) 의 값을 가진다.
85를 RGB 범위인 255로 나누게 되면 0.33333... 의 값이 나온다.
컴퓨터에서는 32비트 범위에서 잘리게 되므로 약간의 소수점 변동이 생길 수 있다.
텐서의 경우 0.33333334 의 값을 가지게 되었다.
149를 255로 나눠보면?
0.5843137254 ... 값이 나온다. 이도 소수점 7번째 자리까지 동일한 값이 나오는 것을 확인 가능하다.
다르게 생각해 보면 R 채널에서는 회색 범위는 153의 값을 가지고, 보라색 범위는 85의 값을 가지는 텐서들로 이루어져 있다.
G 채널에서도 같다.
B 채널에서만 회색 범위가 153이라는 값을 가지고, 보라색 범위가 149의 값을 가지게 된다. 그래서 값 차이가 크게 나지 않는다.
아무튼 다시 이미지로 변경을 한다.
import torchvision.transforms as transforms
import torch
from PIL import Image
# Load the image
image_path = "./img.png"
image = Image.open(image_path)
# Define the transformation
transform = transforms.Compose([
transforms.ToTensor()
])
# Convert the image to a tensor
image_tensor = transform(image)
print(image_tensor.shape)
tf = transforms.ToPILImage()(image_tensor).show()
변형한 것이 없기 때문에 깔끔하게 다시 나온다.
이건 기존에 했던 이미지 - > 바이트 배열 -> 텐서 -> 넘파이 배열 -> 텐서 -> 이미지 변환이다.
from PIL import Image
import torchvision.transforms as transforms
import torch
import numpy as np
# 이미지 불러오기
image_path = "./img.png"
image = Image.open(image_path)
# 이미지 전처리
transform = transforms.Compose([
transforms.Resize((28, 28)), # 모델의 입력 크기로 리사이즈
transforms.ToTensor() # 텐서로 변환
])
image_tensor = transform(image) # 텐서 변환
image_tensor = image_tensor.unsqueeze(0) # 배치 차원 추가
# 텐서를 바이트 값으로 변환하여 바이트 파일로 저장
tensor_bytes = image_tensor.numpy().tobytes() # 텐서를 numpy 배열로 변환 후 바이트로 변환
# 바이트 파일 저장
with open("D:/tensor_values.bytes", "wb") as f:
f.write(tensor_bytes)
# 바이트 파일을 읽어 텐서로 변환
with open("D:/tensor_values.bytes", "rb") as f:
tensor_bytes = f.read()
# 바이트 데이터를 numpy 배열로 변환
tensor_array = np.frombuffer(tensor_bytes, dtype=np.float32)
tensor_array = tensor_array.reshape((1, 3, 28, 28)) # 원래 텐서의 형태로 변환
# numpy 배열을 텐서로 변환
reconstructed_tensor = torch.tensor(tensor_array)
# 텐서를 이미지로 변환
reconstructed_image = transforms.ToPILImage()(reconstructed_tensor.squeeze(0))
# 이미지 저장
reconstructed_image.save("D:/reconstructed_image.jpg")

이미지에 잡음이 좀 생긴 것을 확인할 수 있었다.
'취미 & 아무거나' 카테고리의 다른 글
| [Compiler] Liveness analysis w. CFG (0) | 2024.06.17 |
|---|---|
| [Sensor] TF-LC02 LiDAR sensor Quickstart (0) | 2024.06.11 |
| [YOLOv8] YOLOv8n 내부 가중치 확인하기 (0) | 2024.06.04 |
| [YOLOv8] YOLOv8n 맛보기 + 커스텀 데이터셋 (0) | 2024.06.03 |
| [Keyboard] Nuphy TES68 (0) | 2024.05.13 |