3번에서 이어서 간다.
Instruction Fetch
CV32E40P의 IF 단계는, 외부 버스 인터페이스가 한 사이클에 한 번씩 fetch 요청을 처리할 수 있다면 한 사이클에 하나의 명령어를 ID 단계로 공급할 수 있다.
만약 압축 명령어(C extension)를 실행하는 경우, ID 단계에서 평균적으로 명령어 1개당 32비트 fetch 요청이 1개 보다 적게 필요하다.
최적의 성능 및 타이밍을 위해 Prefetch buffer 가 사용된다.
이 Prefetch buffer는 외부 버스 인터페이스를 통해 외부 명령어 메모리 또는 명령어 캐시 등에서 명령어를 가져온다.
Prefetch buffer는 32비트 정렬된 Prefetch 동작을 수행하고, 가져온 명령어 워드를 FIFO 구조로 저장한다.
이 FIFO의 엔트리 개수는 로컬 파라미터(DEPTH, default : 2, cv32e40p_prefetch_buffer.sv 에서 정의)에 따라 달라진다.
이러한 (추측하는) Prefetch buffer 로 인해, CV32E40P는 코드 영역 바깥까지 DEPTH 워드만큼 명령어를 미리 fetch 할 수 있다. 따라서, 실제 코드 영역 밖을 미리 읽음으로써 의도치 않은 read side-effect 가 발생하지 않도록 주의해야 한다.
표 64는 명령어를 가져올 때 사용되는 신호들에 대해 설명한다.
또한 버스 연결된 인터페이스에는 쓰기 신호가 없기 때문에 Ld/St unit보다 더 단순하다.
| 신호 | 방향 | 설명 |
| instr_addr_o[31:0] | output | 워드 정렬된 주소 |
| instr_req_o | output | 요청이 유효한지, instr_gnt_i 가 한 사이클동안 high 가 될 때 까지 high 로 유지 |
| instr_gnt_i | input | 다른 곳에서 요청을 승인함. instr_addr_o가 다음 사이클에 바뀜 |
| instr_rvalid_i | input | instr_rvalid_i가 high일 때 instr_rdata_i가 유효한 데이터를 가짐. 이 신호는 요청마다 정확히 한 사이클만 high가 됨. |
| instr_rdata_i[31:0] | input | 메모리에서 데이터를 읽음 |
Misaligned Accesses
외부적으로 IF 인터페이스는 항상 32비트 정렬된 명령어 fetch 만 수행한다.
만약 instruction fetch 주소가 워드 정렬되지 않았다면(즉, misaligned fetch 라면)
두 번의 워드 정렬 fetch로 해당 명령어를 읽어온다.
코어 내부적으로는, 워드 정렬과 하프워드 정렬 주소 모두를 처리할 수 있어서 Compress instruction도 지원 가능하다.
내부적으로는 instruction address의 LSB는 무시된다.
--> 32비트 명령어는 항상 4바이트 단위 정렬, 16비트 압축 명령어는 항상 2바이트 단위로 정렬됨. 따라서, 어떤 명령어가 오던 간에 내부에서는 [0]번 비트가 항상 0이기 때문에 무시된다는 것.
ex) 외부 fetch:
1) 주소가 0x1002(하프워드 정렬)이면(32비트 명령어를 읽어야 하는 상황)
2) 0x1000, 0x1004 두 번의 워드 정렬 fetch 를 해서 명령어를 조합
내부 처리:
1) 0x1000 / 0x1002 모두 처리 가능
2) 내부에서는 LSB 무시(0x1000, 0x1002 --> 내부적으로 같은 fetch 처리)
Protocol
CV32E40P 명령어 fetch 인터페이스는 아래의 OBI(Open bus interface) 신호들을 지원하지 않는다.
- we
- be
- wdata
- auser
- wuser
- aid
- rready
- err
- ruser
- rid
이 신호들은 OBI specification 에 정의된 옵션 신호이며, CV32E40P에서는 해당 신호들이 사용되지 않고, OBI specification에 따라 tie-off(상수값 고정)된 상태로 간주된다.
트랜잭션 순서(Transactions Ordering)에 대해 설명하자면,
CV32E40P의 명령어 fetch 인터페이스는 최대 DEPTH개까지 미처리(Outstanding) 트랜잭션을 생성할 수 있다. OBI 명세에 따르면, 마스터 입장에서는 항상 순차적(in-order)로 링크가 유지되어야 한다.
하지만 fetch 인터페이스는 트랜잭션 ID(aid)를 생성하지 않으므로, 인터커넥트(버스 중계기 등)에서 응답이 요청 순서와 동일하게 되돌아오도록 자체적으로 추가 정보를 이용해 순서를 맞춰줘야 한다.
아래는 프로토콜의 타이밍도 예제이다.

그림. 6
CC 2에서 request 가 high 상태 & grant 도 high ==> 요청이 즉시 수락됨
CC 3일 때 rvalid가 high 상태 ==> 그 시점의 데이터들이 전송됨(instr_rdata_i)
연속적인 파이프라인 동작을 보여줌. (요청마다 곧바로 응답)
그림. 7
CC 2에서 request가 high 상태 & grant 도 high ==> 요청 즉시 수락
하지만 rvalid는 high로 뜨지 않았기 때문에 데이터가 나가지는 않음
CC 4에서 request가 low 되고, request가 일단 종료.
CC 5에서 rvalid가 high, 처음의 트랜잭션이 처리됨.
CC 6에서 새로운 request가 들어옴과 동시에 처음에 있었던 트랜잭션이 모두 완료
.. 반복
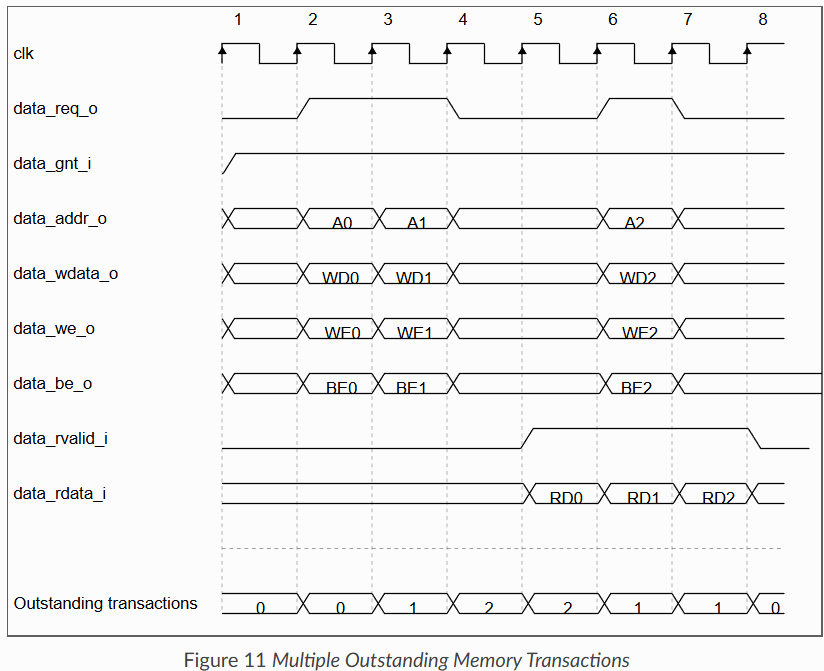
메모리 병목이 존재하면 Outstanding transactions 가 늘어난다는 것을 볼 수 있음.
Load / Store Unit (LSU)
코어의 LSU는 데이터 메모리 접근을 담당한다.
LSU는 워드, 하프워드, 바이트 단위의 Ld / St 명령을 모두 지원한다.
CV32E40P의 데이터 인터페이스는 최대 2개의 outstanding(미완료) 트랜잭션까지 발생시킬 수 있다.
추가적인 outstanding 요청을 허용하는 FIFO 버퍼는 없다.
다음 표는 LSU에서 사용되는 신호들이다.
| 신호 | 방향 | 설명 |
| data_addr_o[31:0] | output | 주소 |
| data_req_o | output | 유효한 요청, data_gnt_i가 한사이클로 high 될 때 까지 high로 유지 |
| data_gnt_i | input | 다른 쪽에서 요청을 수락. data_addr_o가 아마 다음 사이클에 변할 것임. |
| data_we_o | output | 쓰기 활성화, high = 쓰기 / low = 읽기. data_req_o랑 같이 전송됨 |
| data_be_o[3:0] | output | byte 활성화. AXI의 Strobe와 동일한 역할. 어떤 바이트를 읽고 쓸지 결정, data_req_o와 같이 전송됨. |
| data_wdata_o[31:0] | output | 메모리에 쓰여야 할 값, data_req_o와 같이 전송됨. |
| data_rvalid_i | input | data_rvalid_i 신호는 read와 write 트랜잭션 모두에서 response phase의 종료를 알리기 위해 정확히 1사이클 동안 high가 된다. 즉, data_rvalid_i가 1이 되는 그 순간이 해당 트랜잭션의 완료 타이밍이다. |
| data_rdata_i[31:0] | input | 메모리에서 읽은 데이터 |
Misaligned Accesses
LSU는 주소 정렬 예외를 발생시키지 않는다.
즉, 비정렬되었더라도 예외 없이 연산을 수행한다.
만약, Load/Store 대상 데이터가 워드 경계를 넘는 경우, 해당 명령어는 두 번의 버스 트랜잭션으로 나뉘어 수행된다.
하나의 load/store 명령어가 두 번의 버스 트랜잭션이 필요한 경우:
1) 워드 접근인데 주소가 워드 정렬이 아닌 경우
2) 하프워드 접근인데, 주소가 워드 경계를 넘는 경우
두 경우 모두, 낮은 주소에 대한 전송을 먼저 수행한 뒤, 그 다음에 높은 주소에 대한 전송을 진행한다.
Protocol
CV32E40P 데이터 인터페이스는 다음의 OBI 신호들을 구현하지 않는다:
- auser
- wuser
- aid
- rready
- err
- ruser
- rid
이 신호들은 OBI specification에 따라 연결 해제(tied off) 된 것으로 간주할 수 있다.
트랜잭션 순서
앞서 언급했던 것 처럼, 데이터 인터페이스는 최대 2개의 미처리 트랜잭션(outstanding transaction)을 생성할 수 있다.
OBI specification 에서는 마스터 관점에서 링크가 항상 순서대로(in-order) 동작해야 한다고 규정한다.
따라서 데이터 인터페이스가 트랜잭션 ID(aid)를 생성하지 않으므로, 인터커넥트(infrastructure)가 자체적으로 추가 정보를 부가하여 응답이 전송 순서와 동일하게 도착하도록 보장해야 한다.
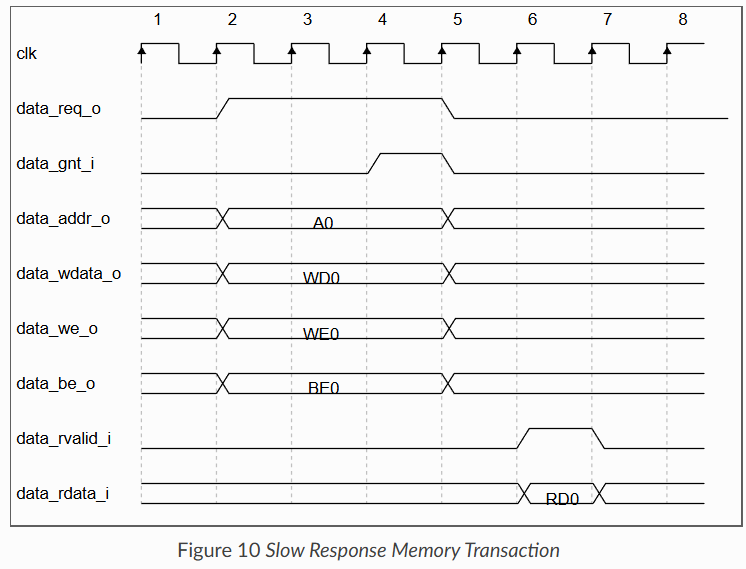
LSU가 메모리와 통신할 때 사용하는 OBI 프로토콜의 동작 방식은 다음과 같다:
1) LSU가 유효한 주소를 data_addr_o에 출력하고, 제어 정보는 data_we_o, data_be_o로 제공하며, data_req_o를 High 로 설정한다.
2) 메모리는 요청을 처리할 준비가 되면 data_gnt_i 를 High 로 올린다. 이 타이밍은 요청이 오기 전일 수도 있고, 후일 수도 있다. (언제나 high면 지속적인 데이터 처리가 가능하다.)
3) 요청이 승인(grant)된 이후에는, LSU가 그 다음 클럭 사이클에 주소 신호를 변경해도 상관없다.
왜냐하면, 메모리가 이미 해당 정보를 내부적으로 처리 및 저장했다고 가정하기 때문이다.
4) 요청이 승인된 뒤, 메모리는 data_rvalid_i 를 High로 올려서 data_rdata_i가 유효함을 알린다. 이는 요청 승인 후 한 사이클 이상 지연될 수 있다.
5) 주의점 : data_rvalid_i는 write 트랜잭션의 경우에도 응답(response) 단계가 끝났음을 알리기 위해 High로 올라가야 하며, 이때 data_rdata_i의 값은 의미 없다.(don't care)
6) 만약 여러개의 승인된 요청이 미처리(outstanding) 상태라면, 메모리가 요청을 순서대로 유지한다고 가정하며, 각각의 요청에 대해 발행한 순서대로 data_rvalid_i가 high가 된다.
다음은 프로토콜의 타이밍도 예제이다.


Post-Incrementing Load / Store Instructions
COREV_PULP == 1인 경우에만 해당된다 (PULP Custom Extension)
Post-incrementing load/store 명령어는 데이터 메모리에서 로드 또는 스토어 연산을 수행하면서, 동시에 베이스 주소를 지정된 오프셋만큼 증가시킨다.
메모리 접근 시에는 오프셋이 적용되지 않은 베이스 주소를 사용한다.
해당 명령어를 사용하면, 일반적인 루프에서 자주 나타나는 규칙적인 데이터 접근 패턴의 코드에서 필요한 명령어 수를 줄일 수 있다. 이러한 명령어는 메모리 접근 명령어에 주소 증가 기능을 내장시켜 별도의 포인터 연산 명령어가 필요 없게 해 준다.
이를 하드웨어 루프 확장과 결합하면, 루프 오버헤드를 크게 줄일 수 있다.
예시)
int sum = 0;
int* ptr = arr;
for (int i = 0; i < 8; i++) {
sum += *ptr; // 메모리 읽기
ptr++; // 포인터 증가
}해당 경우 어셈블리 변환 시 로드 + 포인터 증가가 항상 쌍으로 들어감
# pseudo-assembly
sum = 0
ptr = arr
for i = 0 to 7:
sum += LD_POSTINC ptr, 4 # ptr이 가리키는 4바이트(load) 읽고, ptr을 4 증가포인터 처리가 간단해지는 것을 볼 수 있음.
lp.setup loop_label, 8 # 하드웨어 루프 8회 세팅
loop_label:
LD_POSTINC ptr, 4, reg # reg = *ptr, ptr += 4
add sum, sum, reg하드웨어 루프와 같이 동작시에는 다음과 같이 사용됨(어셈블리)
Register file
소스 파일 : rtl/cv32e40p_register_file_ff.sv
CV32E40P는 31개의 32-bit 너비의 레지스터가 x1-x31로 규정되어 있다.
x0은 소위 zero 레지스터로, 다른 회로를 포함하지 않고 읽기만 가능하다.
우리가 사용하는 코어의 레지스터 파일은 3R2W 레지스터 파일(3 Read port, 2 Write port)이다.
레지스터파일은 ID 단계에서 읽어진다. 그리고 WB 단계에서 쓰여진다. (근데 아까 ALU 같은 연산은 EX 단계에서 바로 레지스터 파일로 쓰여진다고 적혀있긴 했다)
Floating point register file
옵션 FPU가 인스턴스화된 경우, ZFINX가 설정되어 있지 않다면, 레지스터 파일은 f0~f31까지의 추가적인 32개 부동소수점 레지스터 뱅크가 확장된다(ZFINX가 설정되었다면 일반 범용 레지스터를 쓸 것이다 .아마도)
이 레지스터들은 기존 레지스터 파일 위에 쌓이는 형태로 구현되며, 한 사이클에 최대 3개의 오퍼랜드만 읽을 수 있다는 제한을 제외하면 동시에 접근이 가능하다(일반 레지스터파일과 동일하다)
각 오퍼랜드의 주소에는 어떤 레지스터파일(정수/부동소수점)에서 읽을 지를 나타내는 선택 신호가 추가되고, 이 신호는 FP 명령어가 디코딩될 때 명령어 디코더가 생성한다.
이 추가 신호를 통해 해당 operand가 정수 레지스터파일에 있는지, FP 레지스터파일에 있는지 결정된다.
포워딩 경로와 Write-back 로직은 정수/부동소수점 연산 모두에서 공유하며, 별도로 복제되지 않는다.
Sleep unit
소스 파일 : rtl/cv32e40p_sleep_unit.sv
Sleep unit은 내부적으로 clock gate 를 포함하고, 이를 제어한다.
이 clock gate는 입력 클럭 clk_i를 차단하거나 전달해서, CV32E40P 내부의 다른 모듈에서 사용할 gated clock을 생성한다.
즉, clk_i를 직접 사용하는 곳은 sleep unit이 유일하며, 나머지 모든 모듈은 sleep unit에서 생성된 gated clock만 사용한다.
--> sleep unit이 clock을 제어하는 가장 핵심적인 역할을 함.
Sleep unit의 클럭 게이팅 동작은 다음 신호들의 영향을 받는다.
1) rst_ni : 리셋 신호
2) fetch_enable_i : 명령어 가져오기 활성화 신호
3) wfi 명령어 (단, COREV_CLUSTER = 0)
4) cv.elw 명령어 (단, COREV_CLUSTER = 1)
5) pulp_clock_en_i (단, COREV_CLUSTER = 1)
다음은 Sleep unit 인터페이스 표다.

Extension을 보통 끄고 사용할거고 클러스터 형태로 만들지 않고 일반 FPGA에서 동작시킬 것이므로
일단 COREV_CLUSTER == 0인 기준으로 봐야 되겠다.
Startup behavior
CV32E40P가 부팅될 때, clk_i는 내부적으로 게이팅되어 차단된다.(이 때 core_sleep_o = 0으로 표시)
- rst_ni(리셋 신호)가 활성화(=0, active low) 되어 있는 동안 clk_i는 게이팅되어 꺼진다.
- rst_ni가 비활성화(=1) 된 후에도, fetch_enable_i가 1이 될 때 까지는 clk_i는 계속 게이팅되어 꺼져 있다.
- fetch_enable_i가 최초로 1로 올라가면, 그 이후에 fetch_enable_i 신호는 다음번 리셋이 걸릴 때 까지 무시된다.
WFI
클러스터를 0으로 사용하면 되는 옵션이다.
wfi 명령어는 특정 조건에서 슬립 모드에 진입하여, 로컬에서 활성화된 인터럽트가 pending(미결정) 상태가 될 때 까지 대기하는 데 사용될 수 있다. wfi의 동작은 mstatus의 글로벌 인터럽트 비트에 영향을 받지 않는다.
아래 조건 중 하나라도 해당되면 wfi는 슬립 모드에 들어가지 않고 일반 nop처럼 실행된다:
1) debug_req_i = 1이거나 디버그 요청이 pending인 경우
2) 코어가 디버그 모드에 있는 경우
3) 코어가 싱글 스테핑(디버깅) 중인 경우
4) 코어가 트리거 매치 (디버깅)가 발생한 경우
5) COREV_CLUSTER = 1인 경우
--> 근데 위에서 디버그 내용 넘어갔는데..
만약 wfi로 인해 슬립 모드에 진입하면, core_sleep_o가 1로 설정되고 clk_i는 내부적으로 게이팅되어 차단된다. 이 상황에서는 clk_i를 외부에서도 차단할 수 있다.
슬립 모드에서 깨어나는 조건은 다음과 같다:
1) 로컬에서 활성화된 인터럽트가 pending 상태가 됨.
2) 디버그 요청이 pending 상태가 됨.
3) 코어가 디버그 모드에 진입
이 중 하나라도 발생하면, core_sleep_o는 0으로 설정되고 clk_i는 내부적으로 더 이상 게이팅되지 않으며, 외부에서도 clk_i를 차단하면 안 되고, 그리고 명령어 실행이 계속된다.
만약 위와 같은 깨어나는 조건이 wfi 명령어와 동시에 발생하면, 깬 상태가 우선권을 가진다(슬립 모드에 진입하지 않는다)

PULP Cluster Extension
넘어간다.
그 외 Core versions and RTL Freeze Rules / Glossary 는 구현에 있어서는 그냥 한번 슥 보고 넘어가면 될 정도인 것 같다~
'코어' 카테고리의 다른 글
| [CV32E40P] 공식 문서 보기 - 3 (0) | 2025.06.02 |
|---|---|
| [CV32E40P] 공식 문서 보기 - 2 (0) | 2025.05.30 |
| [CV32E40P] 공식 문서 보기 - 1 (0) | 2025.05.20 |